

Kalau ngomongin dunia Machine Learning (ML), pasti kamu sering banget dengar dua istilah yang selalu nongol bareng yaitu: Supervised Learning dan Unsupervised Learning. Dua istilah ini tuh bakal jadi topik utama yang dibahas orang-orang pemula yang baru kenal sama artificial intelligence (AI).
Sayangnya, meski sering disebut, nggak semua orang bener-bener paham bedanya. Nah, makannya di artikel satu ini kita bakal bahas bareng pengertian, perbedaan,dan contoh dari Supervised Learning dan Unsupervised Learning.
Sebelum masuk ke perbandingan dua metode pembelajaran ini, ada baiknya kamu harus paham dulu apa itu Machine Learning? Secara sederhana, Machine Learning (ML) adalah cara ngajarin komputer untuk “belajar” dari data. Kalau manusia belajar dari pengalaman, mesin belajarnya dari data. Jadi, makin banyak data yang dikasih, makin pintar juga si mesin dalam mengenali pola dan membuat keputusan.
Supervised dan Unsupervised Learning Bedanya Apa?
Gini Supervised Learning tuh bisa diibaratkan kamu lagi belajar di kelas bareng guru, nah gurunya selalu kasih tahu kamu jawaban yang benar. Kalau Unsupervised Learning kamu disuruh belajar sendiri tanpa ada petunjuk apa-apa. Jadinya kamu harus nemuin pola dan data secara mandiri.
Perbedaan dasar Supervised Learning dan Unsupervised Learning yang paling mendasar adalah label, Kalau Supervised Learning datanya udah ada labelnya, maka si Unsupervised Learning justru nggak ada labelnya. Biar kamu lebih paham, yuk kita bahas sama-sama.
Apa Itu Supervised Learning?
Supervised Learning bisa dibilang sebagai metode “belajar pakai guru”. Di sini, mesin atau komputer bisa kamu ibaratkan kayak murid yang belajar dari kumpulan data. Inget data pada metode ini udah dikasih label.
Misalnya, kamu punya data yang isinya jenis sayuran: wortel, tomat, dan paprika. Setiap data sudah dikasih label sesuai jenisnya. Nah, model ini bakal memahami pola dari data tadi, jadi dia bakal bisa mengenali sayuran baru kalau karakteristiknya mirip.
Contoh: kalau model dikasih gambar sayuran berwarna oranye dan berbentuk panjang, bakal kasih prediksi kalau itu adalah wortel. Nah, beda lagi kalau dikasih sayuran warna hijau bulat, maka si model bakal nebak sayur itu paprika. Makin banyak kamu kasih contoh latihan, model bakal terbiasa dan makin pintar ngenalin pola.
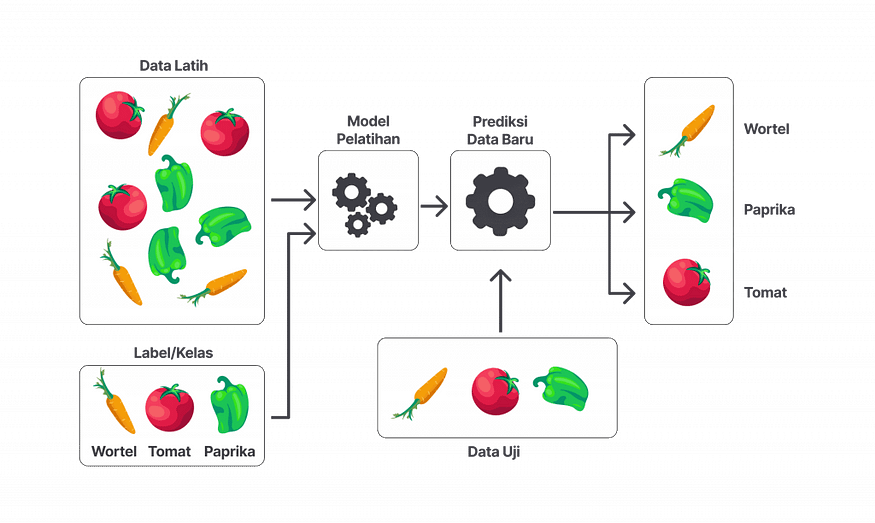
Ciri-Ciri Data Supervised Learning
Dalam Supervised Learning, semua data latih udah dikasih label yang jelas. Misalnya, dalam dataset penjualan buah, setiap entri punya label “Laku Terjual” atau “Tidak Laku Terjual.” Hubungan antara fitur (misal: harga, jenis buah, dan stok) dengan label inilah yang dipelajari oleh model.
Nggak cuma itu, tujuan dari Supervised Learning juga jelas yaitu: bikin prediksi atau klasifikasi yang akurat. Karena data dikasih label secara manual sama manusia, maka hasilnya bisa dipantau dan diverifikasi. Meskipun butuh waktu lama buat kasih label, hasilnya juga bakal lebih sepadan karena model pun lebih terarah dan presisi.
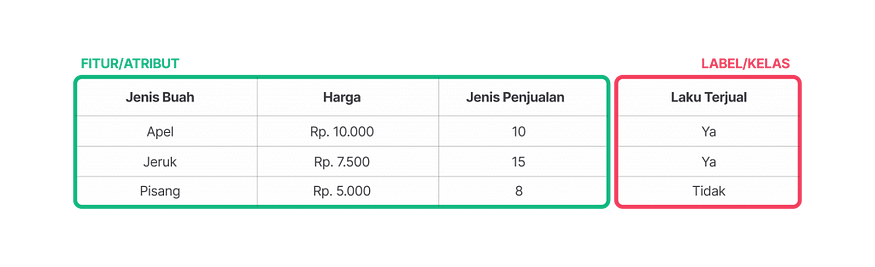
Apa Itu Unsupervised Learning?
Apa itu Unsupervised Learning? Singkatnya adalah belajar tanpa guru. Yup, model ini tuh kebalikannya dari Supervised Learning. Jadi model satu ini belajar sendiri, namun arah, pola, dan makna dari data yang nggak dikasih label sama sekali.
Bayangin kamu dikasih sekumpulan gambar sayur, tapi nggak dikasih tahu mana yang namanya terong, wortel, apalagi paprika. Nah, itu yang kejadian sama Unsupervised Learning, model ini cuma dikasih data tanpa keterangan spesifik.
Nah, tugasnya Unsupervised Learning tuh nyari pola dan mengelompokkan gambar pakai kesamaan visualnya. Unsupervised Learning juga bakal bikin kelompok berdasarkan warna dan bentuk: sayuran hijau bulat masuk kelompok pertama, yang oranye panjang masuk kelompok kedua, dan seterusnya. Habis itu, barulah kami bisa kasih nama tiap kelompok, misalnya “Paprika”, “Wortel”, dan “Bawang”.
Unsupervised Learning juga nawarin kebebasan eksplorasi lebih luas karena nggak ada panduan yang mengikat. Ini cocok dipakai di situasi saat kamu belum tahu pola apa yang tersembunyi di balik data yang besar dan super kompleks.
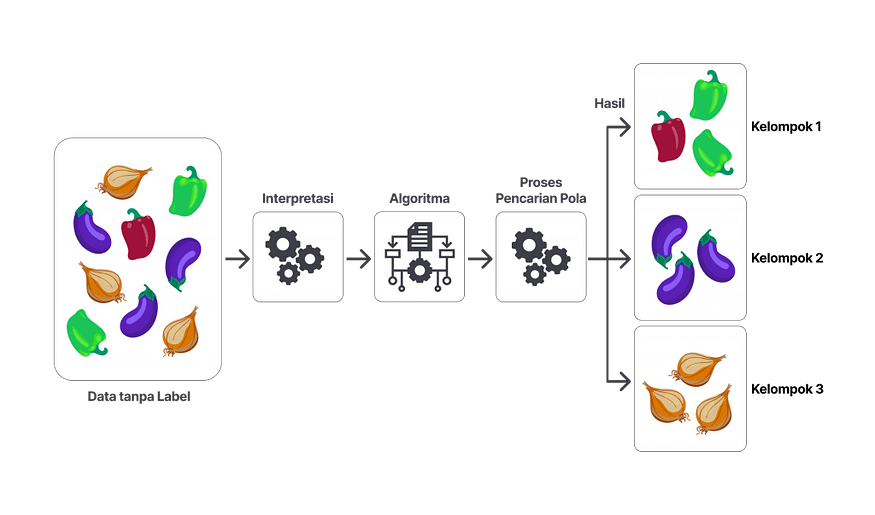
Ciri-ciri Data Unsupervised Learning
Ciri-ciri data Unsupervised Learning yang paling menonjol tuh nggak ada labelnya. Jadi model ini tuh nggak diarahin buat ngeraih tujuan tertentu, tapi disuruh buat nyari pola tersembunyi secara alami. Misal: kalau kamu punya data transaksi pelanggan tanpa label “Jenis Barang”, model bisa otomatis menemukan kelompok pembeli dengan pola belanja yang mirip.
Nggak kaya Supervised Learning, proses model Unsupervised Learning itu nggak butuh campur tangan manusia. Oleh karena itu, model ini lebih cepat dan efisien, meskipun hasilnya nanti agak lebih abstrak, karena model bisa aja menafsirkan sesuai pola dan persepsinya sendiri.
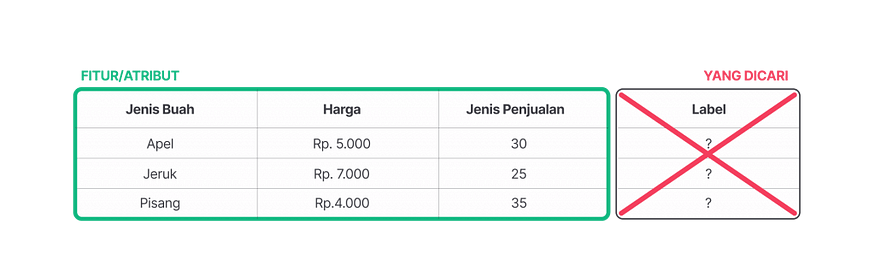
Perbedaan Supervised dan Unsupervised Learning
Kalau kamu liat lebih dalam konsepnya, perbedaan utama Supervised Learning dan Unsupervised Learning terletak pada ada atau tidaknya label data. Supervised Learning bekerja dengan data berlabel dan fokus pada prediksi hasil tertentu, sementara Unsupervised Learning bekerja dengan data tanpa label dan fokus menemukan struktur atau kelompok tersembunyi.
Supervised Learning lebih cocok untuk tugas seperti prediksi harga rumah, deteksi spam, atau diagnosis medis, semuanya butuh hasil yang pasti. Sedangkan Unsupervised Learning cocok untuk clustering pelanggan, analisis perilaku, atau pengelompokan gambar yang sejenis.

Kelebihan dan Kekurangan Keduanya
Supervised Learning tuh unggul di akurasi dan hasil yang lebih terprediksi, soalnya model udah dilatih pakai data yang jelas. Tapi kekurangannya, proses pelabelan bisa memakan waktu lama dan biaya yang nggak sedikit.
Sedangkan Unsupervised Learning itu unggul di eksplorasi data yang besar tanpa perlu label, waktu yang dibutuhkan juga nggak terlalu lama. Tapi kekurangannya ada di hasil yang bisa aja susah diinterpretasikan, karena nggak ada acuan pasti.
Jadi kesimpulan pilih Supervised Learning atau Unsupervised Learning? Jawabannya adalah sesuai kebutuhan, Kalau kamu lagi butuh prediksi yang jelas ya pilih Supervised. Tapi kalau kamu pingin dapet pola baru yang masih mentah maka paling pas pakai Unsupervised Learning.

Algoritma Supervised dan Unsupervised Learning
Supervised Learning
Supervised Learning tuh punyadua model utama yaitu: Classification dan Regression.
Classification itu kayak otak AI yang belajar dari contoh buat nebak kategori sesuatu. Jadi dia tahu mana email yang spam, mana yang aman, bisa bedain foto kucing sama anjing, bahkan bantu dokter nebak penyakit dari gejala. Intinya, dia jago banget ngenalin pola dari data yang udah dikasih label!
Beberapa algoritma yang lagi hits buat tugas ini antara lain :
- K-Nearest Neighbors (KNN): KNN itu kayak nyontek temen paling mirip. Kalau mayoritas dari “tetangga terdekat” milih A, ya udah, datanya ikut A juga. Simpel: liat siapa yang paling deket, trus ikut mayoritas.
- Support Vector Machine (SVM): SVM tuh jago bikin batas paling adil antara dua kubu data. Kalau garis lurus nggak cukup, dia bakal “naikin level” datanya ke dimensi lebih tinggi biar bisa misahin dengan sempurna.
- Decision Tree & Random Forest: Decision Tree itu kayak main tebak-tebakan berurutan: “Kalau iya ke sini, kalau nggak ke sana.” Sedangkan Random Forest versi upgrade-nya, banyak pohon yang mikir bareng biar hasilnya lebih akurat dan nggak bias.
- Logistic Regression: Namanya emang regression, tapi tugasnya buat klasifikasi. Dia ngitung peluang sesuatu terjadi, misal 0.8 artinya 80% kemungkinan “iya”. Kayak feeling digital yang lumayan akurat.
Sementara itu, Regression punya vibe yang beda karena tugasnya bukan nebak kategori, tapi memperkirakan angka yang bisa berubah-ubah. Bayangin kayak nyoba prediksi harga rumah, jumlah penjualan, atau berapa orang yang bakal beli skincare minggu depan. Algoritma yang sering dipakai ada:
- Polynomial Regression: Versi lebih fleksibel dari linear, bisa ngikutin pola data yang belok-belok, nggak harus lurus doang.
- Decision Trees: Kayak pohon keputusan yang ngebagi data jadi bagian kecil biar bisa nebak nilai dengan logika “kalau ini, maka itu.”
- Random Forest: Kumpulan banyak pohon keputusan yang kerja bareng biar hasil prediksinya makin akurat dan nggak ngasal.
- Support Vector Regression (SVR): Mirip SVM, tapi fokusnya bukan ngelompokkan data, melainkan nebak angka secara presisi.
Unsupervised Learning
Unsupervised Learning itu kayak AI yang belajar sendiri tanpa guru. Ada dua algoritma utama yaitu Clustering dan Dimensionality Reduction.
Clustering itu kayak AI jadi detektif yang ngelompokkan data berdasarkan kemiripan. Contohnya, ngelompokkan pelanggan dengan pola belanja yang mirip atau foto yang punya vibe visual sama.
Algoritma yang sering dipakai antara lain:
- K-Means Clustering : Ibaratnya kayak AI yang suka bikin geng. Kamu tentuin dulu mau ada berapa geng (K), lalu dia bakal ngelompokkin data berdasarkan siapa yang paling mirip. Terus pusat gengnya (centroid) bakal terus geser sampai nemu posisi paling pas. Hasilnya? Data yang mirip bakal nongkrong bareng di grup yang sama.
- Hierarchical Clustering: algoritma satu ini bisa diibaratkan versi “pohon keluarga” dari clustering. Dia bikin struktur bertingkat yang nunjukin hubungan antar data, dari yang paling deket sampai paling jauh. Bisa mulai dari bawah ke atas (gabungin data mirip) atau dari atas ke bawah (pecah jadi kelompok kecil). Visualisasinya kayak pohon data yang rapi banget.
- DBSCAN: bisa disebut sebagai algoritma yang jago ngelompokkin data berdasarkan “kepadatan”. Kalau ada banyak data yang deketan, mereka masuk satu geng. Tapi kalau ada yang sendirian, langsung dicap outlier. Kerenya lagi, DBSCAN nggak butuh jumlah cluster di awal dan tetap jago meski datanya berantakan.
- Gaussian Mixture Models (GMM): GMM tuh lebih fleksibel, kayak bilang “nggak harus 100% di satu kelompok kok.” Jadi setiap data bisa punya kemungkinan gabung ke beberapa cluster sekaligus. Misalnya 70% di A dan 30% di B. Cocok banget buat data yang batas antar kelompoknya nggak jelas tapi tetap pengen dibagi dengan gaya elegan.
Nah, kalau Dimensionality Reduction tuh kayak ngeringkas data biar lebih sederhana tapi tetap informatif. Teknik ini sering dipakai buat visualisasi atau tahap awal sebelum training. Beberapa algoritma populernya ada: PCA, t-SNE, LDA, dan Autoencoders yang jago bikin data kompleks jadi lebih ringan tanpa kehilangan maknanya.
Kesimpulan
Kalau kamu pengin benar-benar paham dunia Machine Learning, kamu wajib kenalan sama dua sahabat beda gaya: Supervised Learning dan Unsupervised Learning. Keduanya kayak dua sisi koin yang sama, tapi punya peran yang saling melengkapi buat bikin AI makin cerdas. Supervised itu kayak kamu belajar dari contoh dan arahan, jadi hasilnya bisa lebih tepat dan akurat. Sementara Unsupervised lebih ke sisi eksploratif yang suka nemuin pola tersembunyi tanpa harus dikasih tahu dulu.
Di zaman yang serba data kayak sekarang, gabungan dua pendekatan ini bisa bikin AI bukan cuma pintar nebak, tapi juga kreatif dalam menemukan hal-hal baru yang sebelumnya nggak kebayang. Jadi, kalau kamu mau beneran ngerti gimana cara kerja AI, mulai aja dari dua fondasi ini. Karena di sinilah semua kecerdasan buatan bermula.




4 komentar untuk “7 Bahasa Pemrograman Paling Dicari di 2026, Kamu Harus Mulai dari Mana?”
Hey very interesting blog!
Materi singkat padat dan jelas, semoga bermafaat
I couldn’t resist commenting. Exceptionally well written!
mantap